
About Me
Greetings! I’m Jiamian Wang, a final-year Ph.D. candidate at Rochester Institute of Technology (RIT), advised by Dr. Zhiqiang Tao as his first Ph.D. student. My research focuses on visual understanding and reasoning, and has appeared at CVPR (Highlight), ECCV (Oral), NeurIPS, ICCV, and TPAMI. Before RIT, I spent a year at Santa Clara University with Dr. Tao; I received my M.S. from USC (2020) and B.E. from Tianjin University (2018).
For a short, rough sketch of my recent research interests, see my Research page.
I expect to graduate in 2026 and am actively seeking full-time opportunities. Feel free to reach out if there's a potential match.
Experience
- NVIDIA — Deep Learning Intern
- Developing OPD-based solutions for VLA-based autonomous-driving model post-training.
- I’m currently on-site at NVIDIA HQ in Santa Clara — always up for a coffee chat if you’re around!
- Adobe Research (Document Intelligence Lab) — Research Scientist Intern
- Mentors: Ruiyi Zhang, Tong Sun
- Built an agent for multi-turn, multimodal document retrieval and question-answering:
- an automated, customized, and scalable data-curation pipeline;
- a complete search-agent training and deployment infrastructure;
- a search agent built upon the curated data and infrastructure.
- Bosch Center for Artificial Intelligence — Machine Learning Research Intern
- Mentors: Chen Qiu, Chaithanya Kumar Mummadi
- Developed visual autoregressive models for low-level vision, studying error accumulation in next-token prediction and a post-processing solution for better visual quality and coherence.
- SenseBrain Technology (SenseTime) — Research Intern
- Developed a one-shot over-exposure pixel calibration method compatible with the Sony quad Bayer sensor.
News
2026.06: [arXiv] DocArena: Turning Raw Documents into Controllable Training Environments for Document Search Agents is now available on arXiv!
2026.06: [IROS’26] Two papers accepted to IROS 2026: Latent-Centroid Steering for command-aligned autonomous driving, and Visual Autoregressive Modeling Through Online Multi-Scale Preference Optimization for low-level image perception.
2026.05: I started as a Deep Learning Intern at NVIDIA, working on VLA-based autonomous-driving model post-training.
2025.10: I passed my Ph.D. proposal defense!
2025.08: [EMNLP’25] Two papers accepted to EMNLP 2025: Visual Self-Refinement for Autoregressive Models (Findings) and X-CoT: Explainable Text-to-Video Retrieval via LLM-based Chain-of-Thought Reasoning (Main).
2025.05: I joined Adobe Research (Document Intelligence Lab) as a Research Scientist Intern, working on agents for multimodal document retrieval and question-answering.
2025.02: [TPAMI] S²-Transformer for Mask-Aware Hyperspectral Image Reconstruction accepted to IEEE Transactions on Pattern Analysis and Machine Intelligence.
2024.10: [NeurIPS’24] I received NeurIPS’24 Travel Award. Thanks to NeurIPS and looking forward to visiting Vancouver!
2024.09: [NeurIPS’24] Two papers are accepted by NeurIPS 2024. One is FedHP, in which we developed a federated learning framework to effectively cooperate cross-silo computational imaging systems without breaking the privacy concern. One is about text-video retrieval, where we devised a diffusion-inspired iterative alignment process to solve for the multimodal modality gap and achieves encouraging performance. Code, pretrained models, and the manuscript will be released soon!
2024.09:I will server as a reviewer for AAAI 2025 and ICLR 2025.
2024.07: [ECCV’24] Our work of SQ-LLaVA has been accepted by ECCV 2024. Congratulations to Guohao!
2024.06: Poster, Video, and Supplementary Material has been released, looking forward to present our work in CVPR2024!
2024.05: I will serve as a reviewer for NeurIPS 2024.
2024.03: I will join Bosch Research and Technology Center as a research intern, focusing on autoregressive image generation, starting from May 2024.
2024.02: [CVPR’24] One paper on multi-modality text-video retrieval is accepted by CVPR 2024 as Highlight (2.8%). Check out the manuscript.
2024.02: I will serve as a reviewer for ECCV 2024.
2023.11: I will serve as a reviewer for CVPR 2024.
2023.08: [ICCV’23] Code, including training, testing scripts, and pretrained models have been released. Check out Iterative-Soft-Shrinkage-SR for more details.
2023.07: [ICCV’23] One paper on efficient image super-resolution (Arxiv) is accepted by ICCV 2023. Looking forward to sharing our work in Paris.
2023.06: [Preprint] Check out our Federated learning method on snapshot compressive imaging, Federated Hardware-Prompt Learning (FedHP). This is the first attempt of discussing the power of FL in the field of SCI.
2023.03: [Preprint] Check out our new pruning method that flexibly handles diverse off-the-shelf SR network architectures without pre-training: Arxiv. Thanks to my co-authors’ great support.
2022.06. [ECCV’22] One paper on uncertainty quantification on SCI system is accpeted as an Oral paper by ECCV 2022 (2.7%). Check out the manuscript and the code.
Selected Publications and Preprints
For a complete list, please see my Google Scholar.
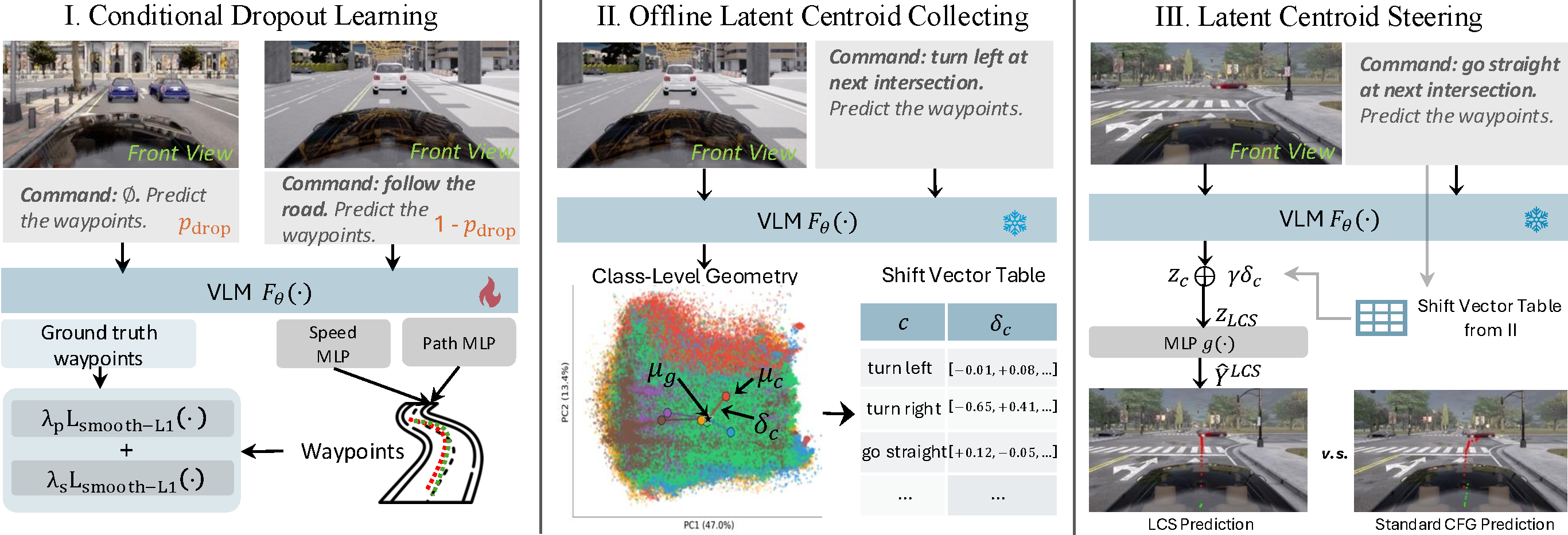 | Latent-Centroid Steering: Single-Pass Classifier-Free Guidance for Command-Aligned Autonomous Driving. Meibo Hu, Jiamian Wang, Pichao Wang, Zhiqiang Tao. IROS, 2026. (Contributed Paper) Paper and code coming soon. |
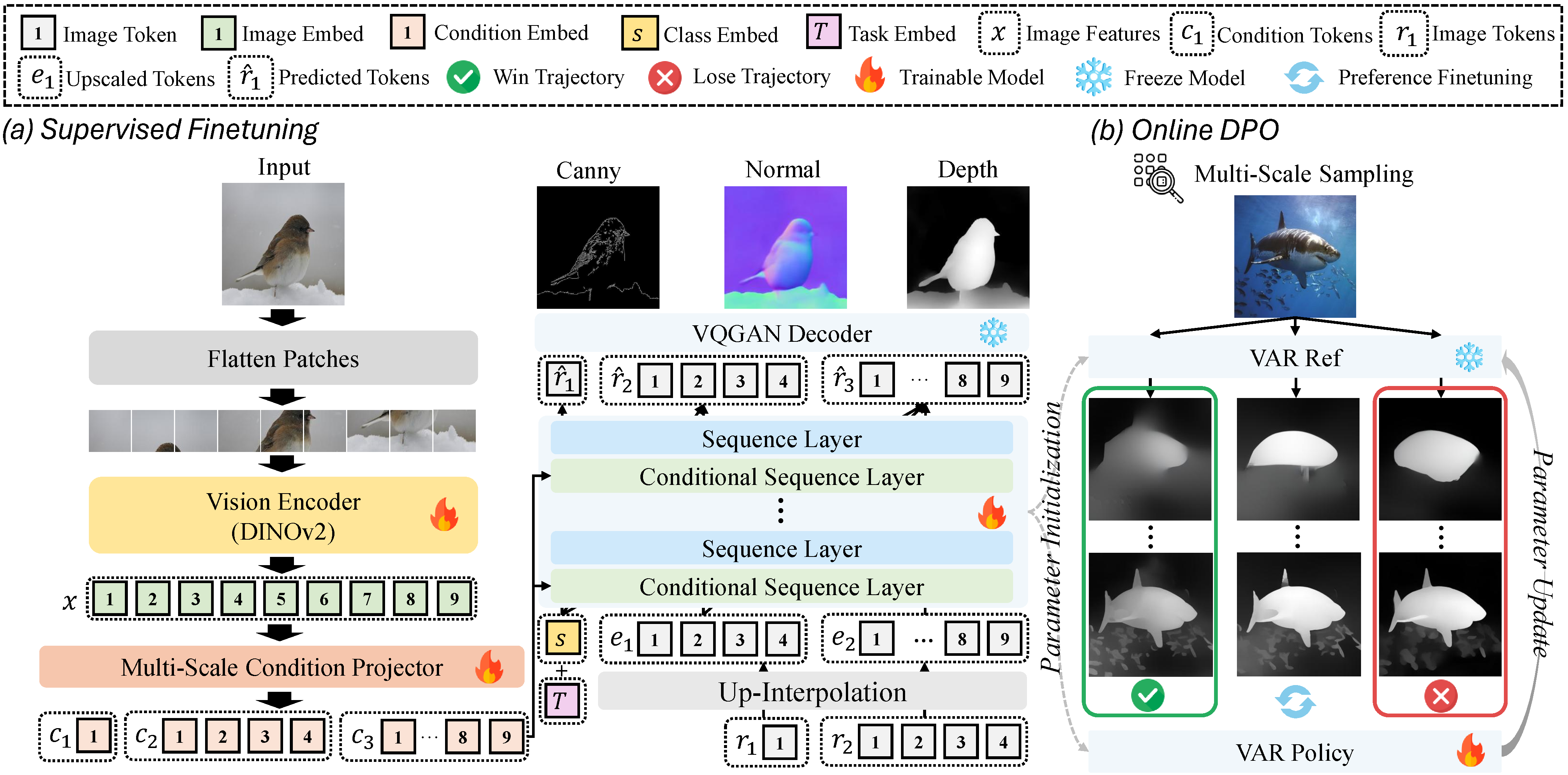 | Visual Autoregressive Modeling Through Online Multi-Scale Preference Optimization for Low-Level Image Perception. Ziqi Zhou, Jiamian Wang, Chen Qiu, Chaithanya Kumar Mummadi, Qi Yu, Zhiqiang Tao. IROS, 2026. (Contributed Paper) Paper and code coming soon. |
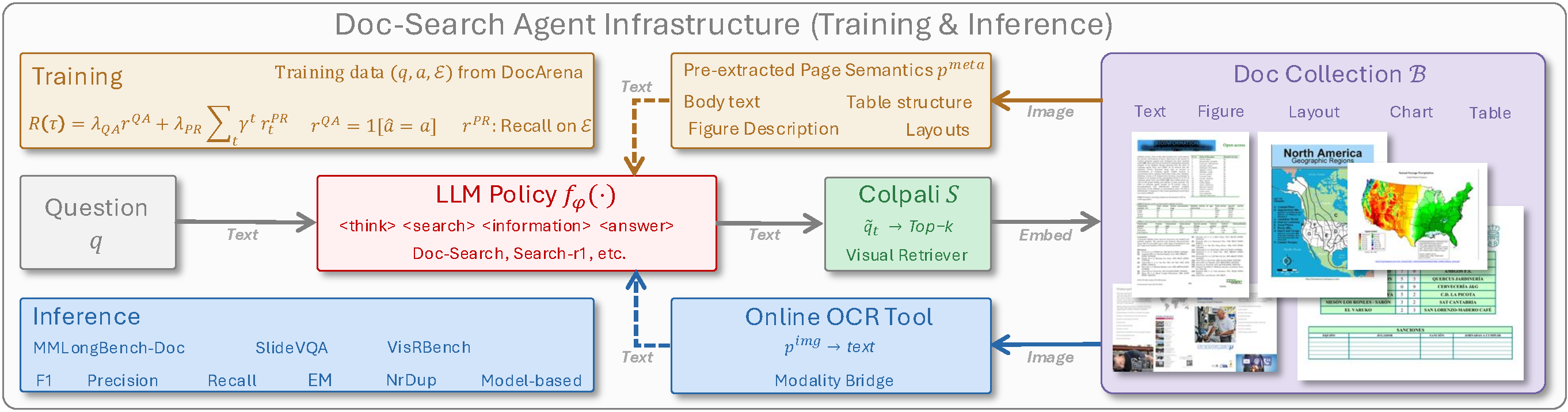 | DocArena: Turning Raw Documents into Controllable Training Environments for Document Search Agents. Jiamian Wang, Ruiyi Zhang, Tong Yu, Jing Shi, Samyadeep Basu, Rajiv Jain, Zhiqiang Tao, Tong Sun. Preprint, 2025. |
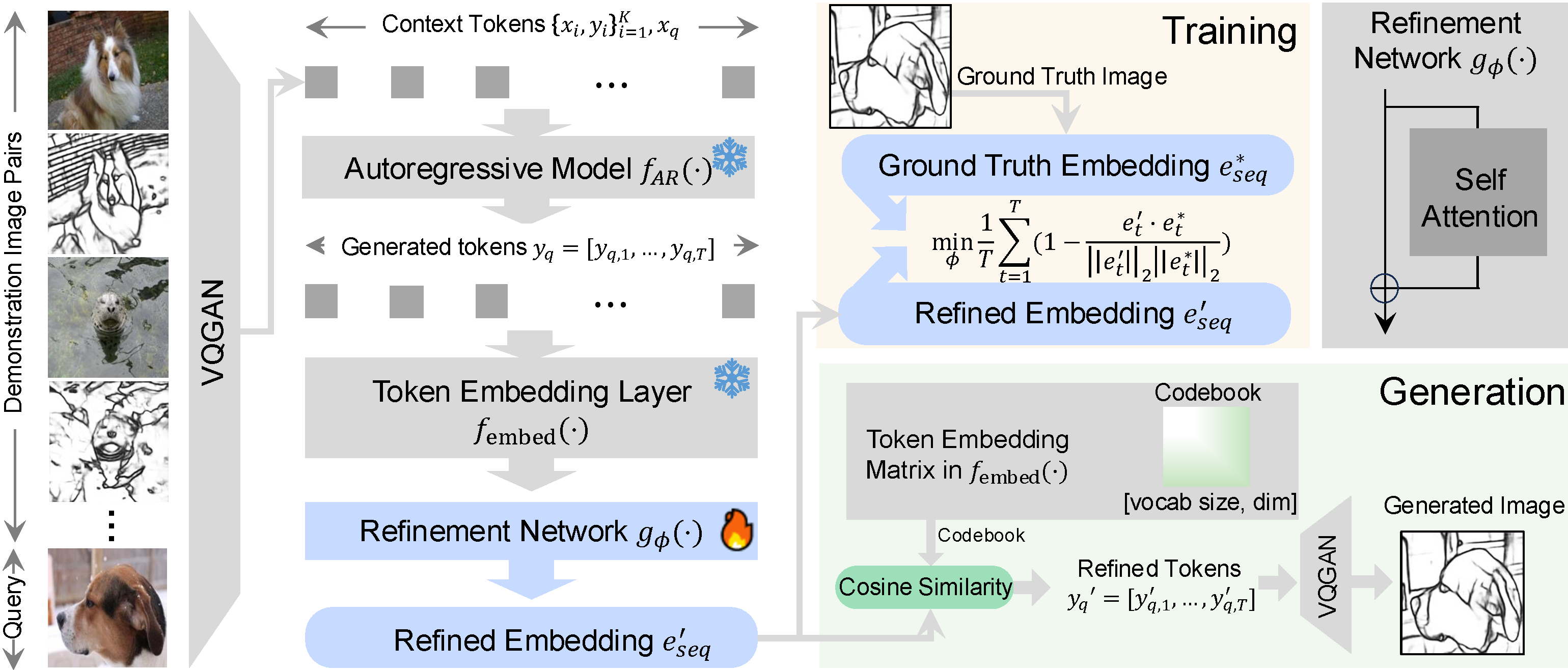 | Visual Self-Refinement for Autoregressive Models. Jiamian Wang, Ziqi Zhou, Chaithanya Kumar Mummadi, Sohail Dianat, Majid Rabbani, Raghuveer Rao, Chen Qiu, Zhiqiang Tao. EMNLP Findings, 2025. |
 | X-CoT: Explainable Text-to-Video Retrieval via LLM-based Chain-of-Thought Reasoning. Prasanna Reddy Pulakurthi, Jiamian Wang, Majid Rabbani, Sohail Dianat, Raghuveer Rao, Zhiqiang Tao. EMNLP Main, 2025. |
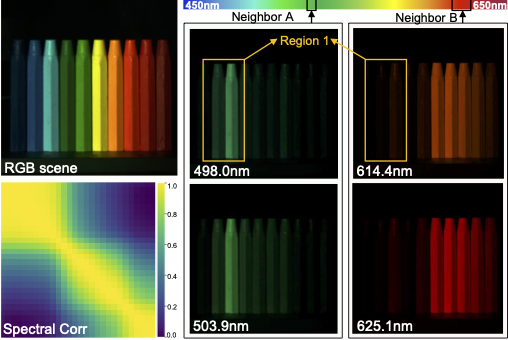 | S²-Transformer for Mask-Aware Hyperspectral Image Reconstruction. Jiamian Wang, Kunpeng Li, Yulun Zhang, Xin Yuan, Zhiqiang Tao. IEEE TPAMI, 2025. |
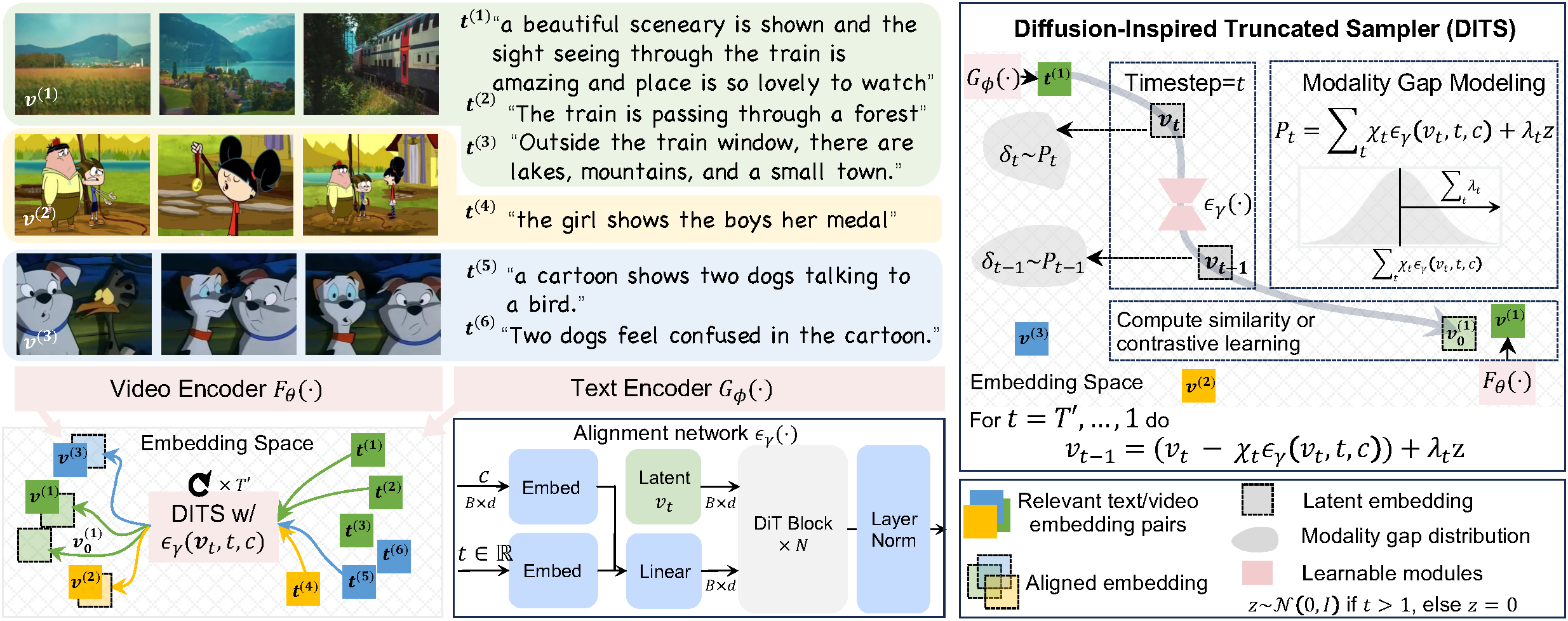 | Diffusion-Inspired Truncated Sampler for Text-Video Retrieval. Jiamian Wang, Pichao Wang, Dongfang Liu, Qiang Guan, Sohail Dianat, Majid Rabbani, Raghuveer Rao, Zhiqiang Tao. NeurIPS, 2024. NeurIPS Scholar Award |
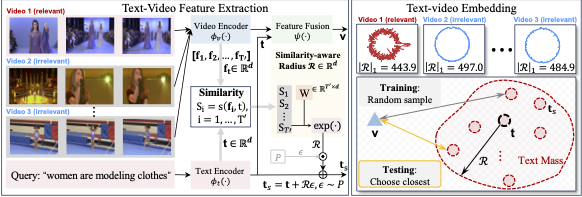 | Text Is MASS: Modeling as Stochastic Embedding for Text-Video Retrieval. Jiamian Wang, Guohao Sun, Pichao Wang, Dongfang Liu, Sohail Dianat, Majid Rabbani, Raghuveer Rao, Zhiqiang Tao. CVPR, 2024. Highlight · 2.8% |
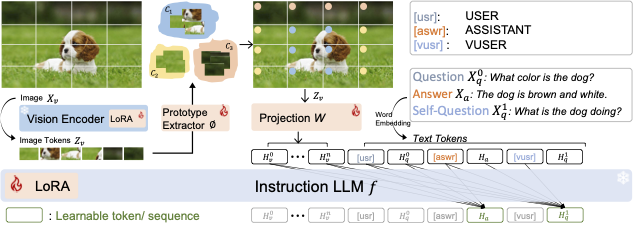 | SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant. Guohao Sun, Can Qin, Jiamian Wang, Zeyuan Chen, Ran Xu, Zhiqiang Tao. ECCV, 2024. |
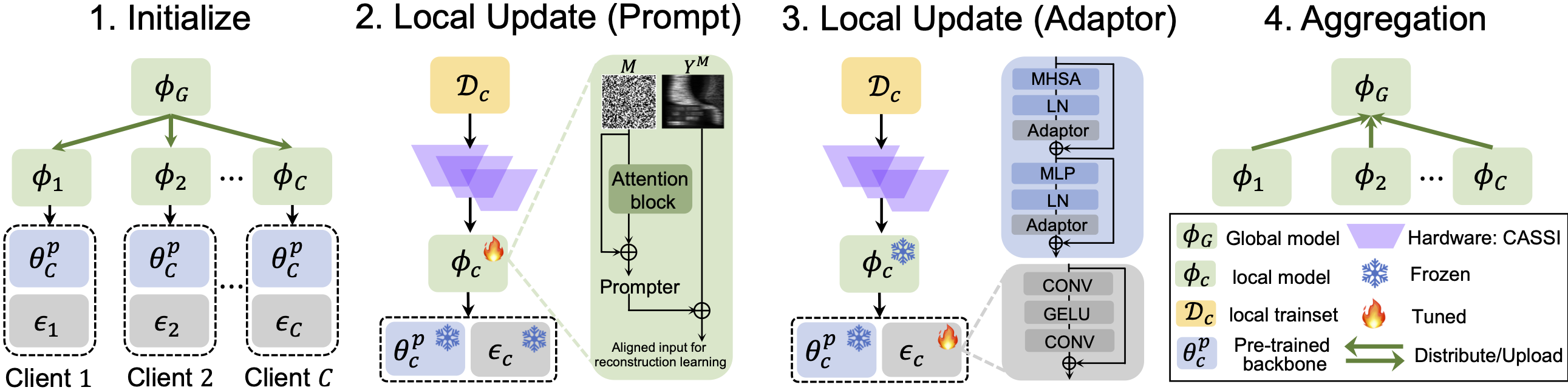 | Cooperative Hardware-Prompt Learning for Snapshot Compressive Imaging. Jiamian Wang, Zongliang Wu, Yulun Zhang, Xin Yuan, Tao Lin, Zhiqiang Tao. NeurIPS, 2024. |
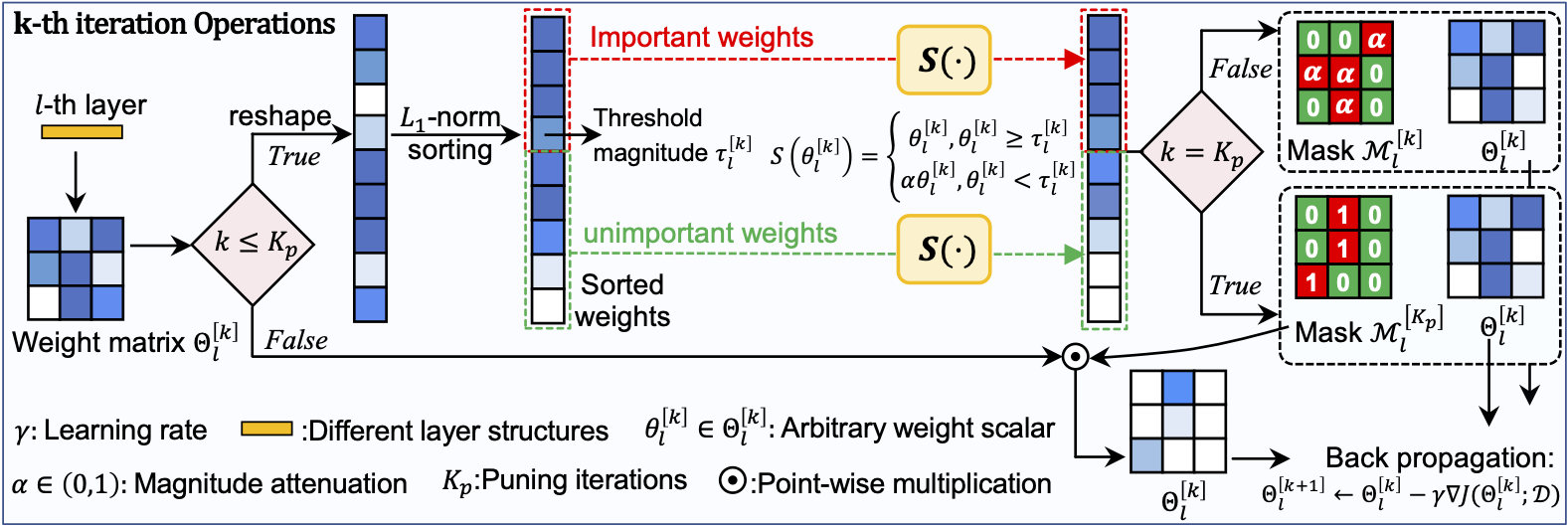 | Iterative Soft Shrinkage Learning for Efficient Image Super-Resolution. Jiamian Wang, Huan Wang, Yulun Zhang, Yun Fu, Zhiqiang Tao. ICCV, 2023. |
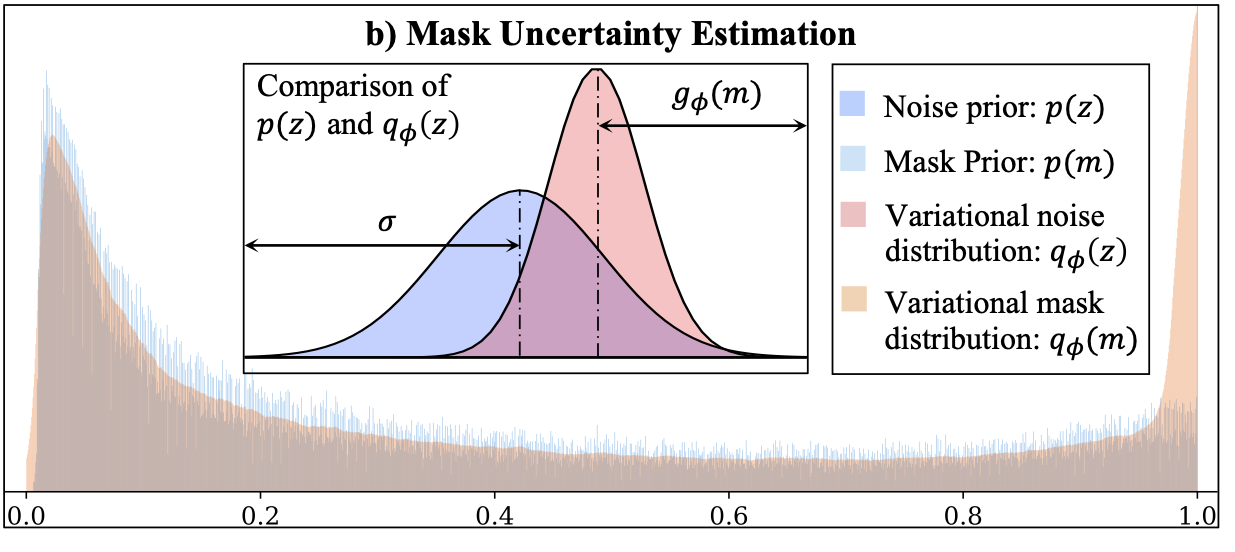 | Modeling Mask Uncertainty in Hyperspectral Image Reconstruction. Jiamian Wang, Yulun Zhang, Xin Yuan, Ziyi Meng, Zhiqiang Tao. ECCV, 2022. Oral · 2.7% |
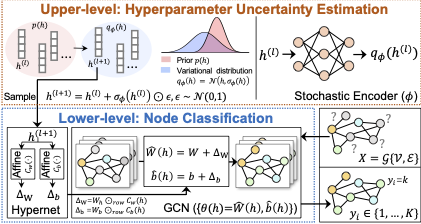 | Calibrate Automated Graph Neural Network via Hyperparameter Uncertainty. Xueying Yang, Jiamian Wang, Sheng Li, Zhiqiang Tao. CIKM, 2022. |
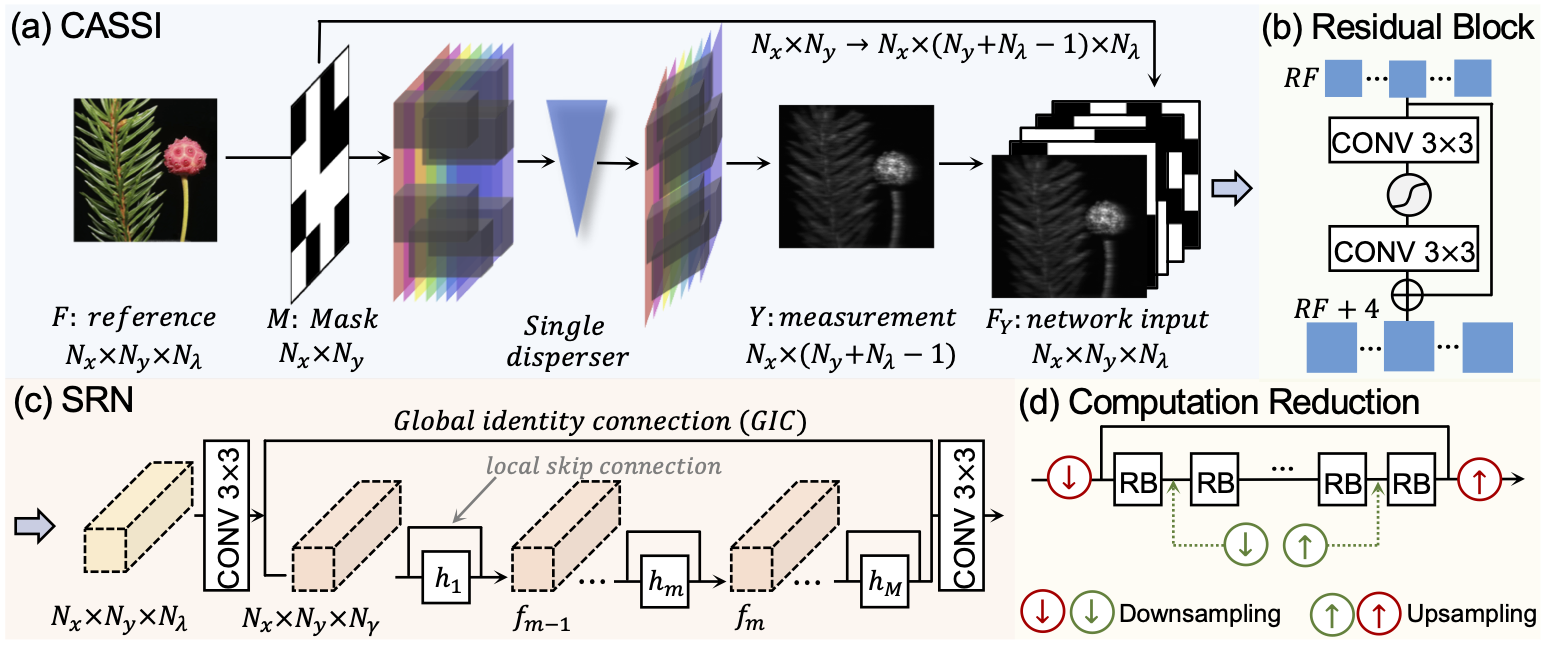 | A new backbone for hyperspectral image reconstruction. Jiamian Wang, Yulun Zhang, Xin Yuan, Yun Fu, Zhiqiang Tao. Arxiv, 2022. |
{kind=link}
Invited Talks
- Recent Advances in Text-Video Retrieval — Twelve Labs, San Francisco, CA
- Snapshot-based Hyperspectral Imaging Meets with Deep Learning — Computer Science and Engineering, Santa Clara University, Santa Clara, CA
Professional Services
- Conference Reviewer: ICLR (2024–2026), CVPR (2024–2026), NeurIPS (2024–2026), AAAI (2023–2025), ECCV (2024, 2026), ICML (2024–2026), CIKM (2021–2023), ACM SIGKDD (2022–2023).
- Journal Reviewer: TPAMI, IJCV, TIP, TNNLS, TMM, TCSVT, Pattern Recognition, TETCI.
Hobbies
Outside of research, I enjoy swimming and kayaking.